如需转载,请根据 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 许可,附上本文作者及链接。
本文作者: 执笔成念
作者昵称: zbcn
本文链接: https://1363653611.github.io/zbcn.github.io/2020/10/10/JCF_04LinkedHashMap/
总体介绍
LinkedHashSet和LinkedHashMap在Java里也有着相同的实现,前者仅仅是对后者做了一层包装,也就是说LinkedHashSet里面有一个LinkedHashMap(适配器模式)。因此本文将重点分析LinkedHashMap。
LinkedHashMap实现了Map接口,即允许放入key为null的元素,也允许插入value为null的元素。从名字上可以看出该容器是linked list和HashMap的混合体,也就是说它同时满足HashMap和linked list的某些特性。可将LinkedHashMap看作采用linkedlist增强的HashMap。
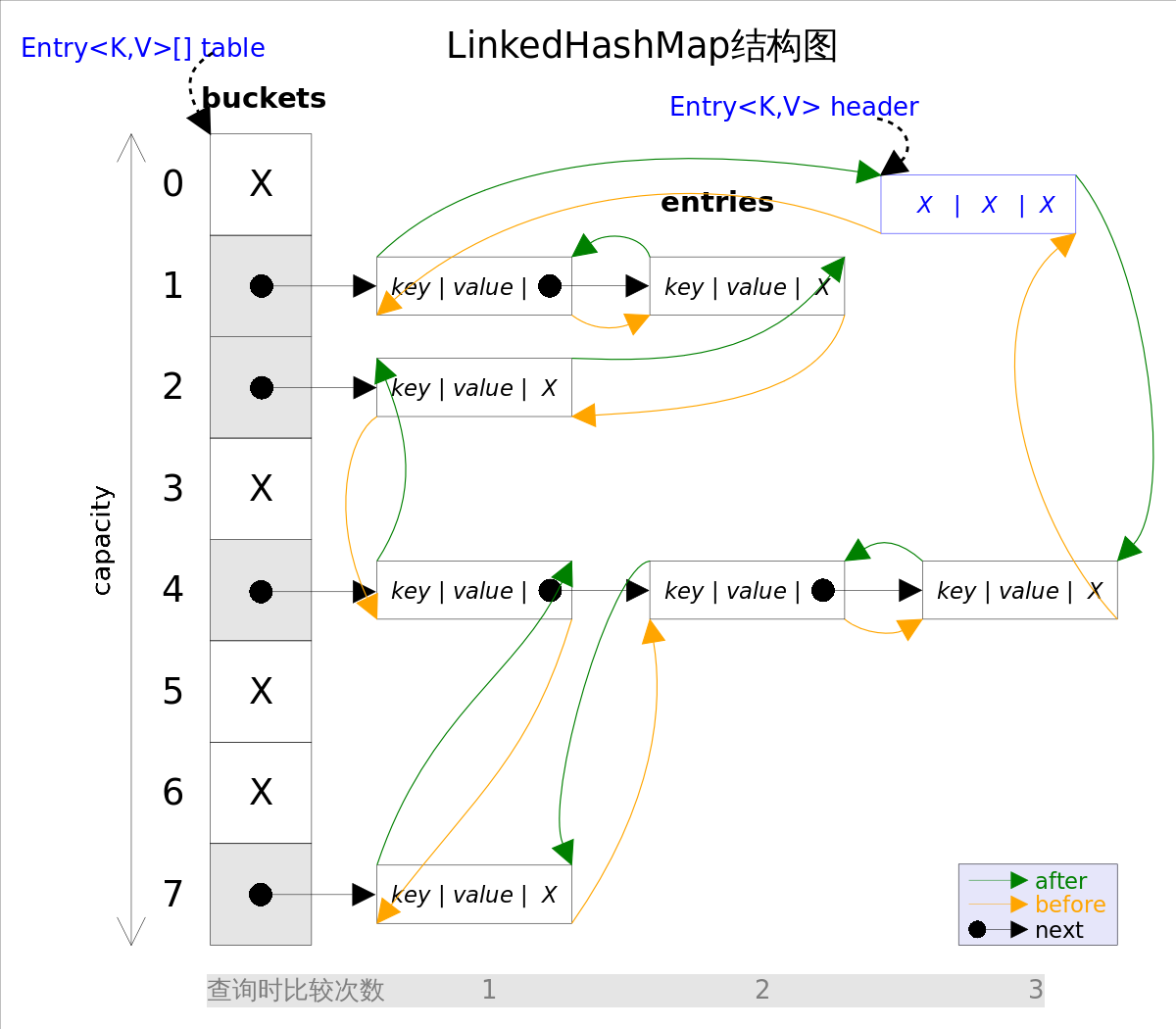
事实上LinkedHashMap是HashMap的直接子类,二者唯一的区别是*LinkedHashMap*在*HashMap*的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同
上图给出了LinkedHashMap的结构图,主体部分跟HashMap完全一样,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。
除了可以保迭代历顺序,这种结构还有一个好处:迭代*LinkedHashMap*时不需要像*HashMap*那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关。
有两个参数可以影响LinkedHashMap的性能:初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。
将对象放入到LinkedHashMap或LinkedHashSet中时,有两个方法需要特别关心:hashCode()和equals()。*hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”**。所以,如果要将自定义的对象放入到LinkedHashMap或LinkedHashSet中,需要@Override*hashCode()和equals()方法。
通过如下方式可以得到一个跟源Map 迭代顺序一样的LinkedHashMap:
1 | void foo(Map m) { |
2 | Map copy = new LinkedHashMap(m); |
3 | ... |
4 | } |
出于性能原因,LinkedHashMap是非同步的(not synchronized),如果需要在多线程环境使用,需要程序员手动同步;或者通过如下方式将LinkedHashMap包装成(wrapped)同步的:
1 | Map m = Collections.synchronizedMap(new LinkedHashMap(...)); |
源码分析
Entry 的继承关系

HashMap 的内部类 TreeNode 不继承它的了一个内部类 Node,却继承自 Node 的子类 LinkedHashMap 内部类 Entry。这里这样做是有一定原因的。LinkedHashMap 内部类 Entry 继承自 HashMap 内部类 Node,并新增了两个引用,分别是 before 和 after。这两个引用的用途不难理解,也就是用于维护双向链表。同时,TreeNode 继承 LinkedHashMap 的内部类 Entry 后,就具备了和其他 Entry 一起组成链表的能力。但是这里需要大家考虑一个问题。当我们使用 HashMap 时,TreeNode 并不需要具备组成链表能力。
get()
LinkedHashMap 重写了get() 方法,在afterNodeAccess()函数中,会将当前被访问到的节点e,移动至内部的双向链表的尾部。
1 | public V get(Object key) { |
2 | Node<K,V> e; |
3 | if ((e = getNode(hash(key), key)) == null) |
4 | return null; |
5 | if (accessOrder) |
6 | afterNodeAccess(e); |
7 | return e.value; |
8 | } |
访问顺序的维护过程
LinkedHashMap 是按插入顺序维护链表。不过我们可以在初始化 LinkedHashMap,指定 accessOrder 参数为 true,即可让它按访问顺序维护链表。当我们调用get/getOrDefault/replace等方法时,只需要将这些方法访问的节点移动到链表的尾部即可.
1 | // LinkedHashMap 中覆写 |
2 | public V get(Object key) { |
3 | Node<K,V> e; |
4 | if ((e = getNode(hash(key), key)) == null) |
5 | return null; |
6 | // 如果 accessOrder 为 true,则调用 afterNodeAccess 将被访问节点移动到链表最后 |
7 | if (accessOrder) |
8 | afterNodeAccess(e); |
9 | return e.value; |
10 | } |
11 | |
12 | // LinkedHashMap 中覆写 |
13 | void afterNodeAccess(Node<K,V> e) { // move node to last |
14 | LinkedHashMap.Entry<K,V> last; |
15 | if (accessOrder && (last = tail) != e) { |
16 | LinkedHashMap.Entry<K,V> p = |
17 | (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; |
18 | p.after = null; |
19 | // 如果 b 为 null,表明 p 为头节点 |
20 | if (b == null) |
21 | head = a; |
22 | else |
23 | b.after = a; |
24 | |
25 | if (a != null) |
26 | a.before = b; |
27 | /* |
28 | * 这里存疑,父条件分支已经确保节点 e 不会是尾节点, |
29 | * 那么 e.after 必然不会为 null,不知道 else 分支有什么作用 |
30 | */ |
31 | else |
32 | last = b; |
33 | |
34 | if (last == null) |
35 | head = p; |
36 | else { |
37 | // 将 p 接在链表的最后 |
38 | p.before = last; |
39 | last.after = p; |
40 | } |
41 | tail = p; |
42 | ++modCount; |
43 | } |
44 | } |
下面举例演示一下,帮助大家理解。假设我们访问下图键值为3的节点
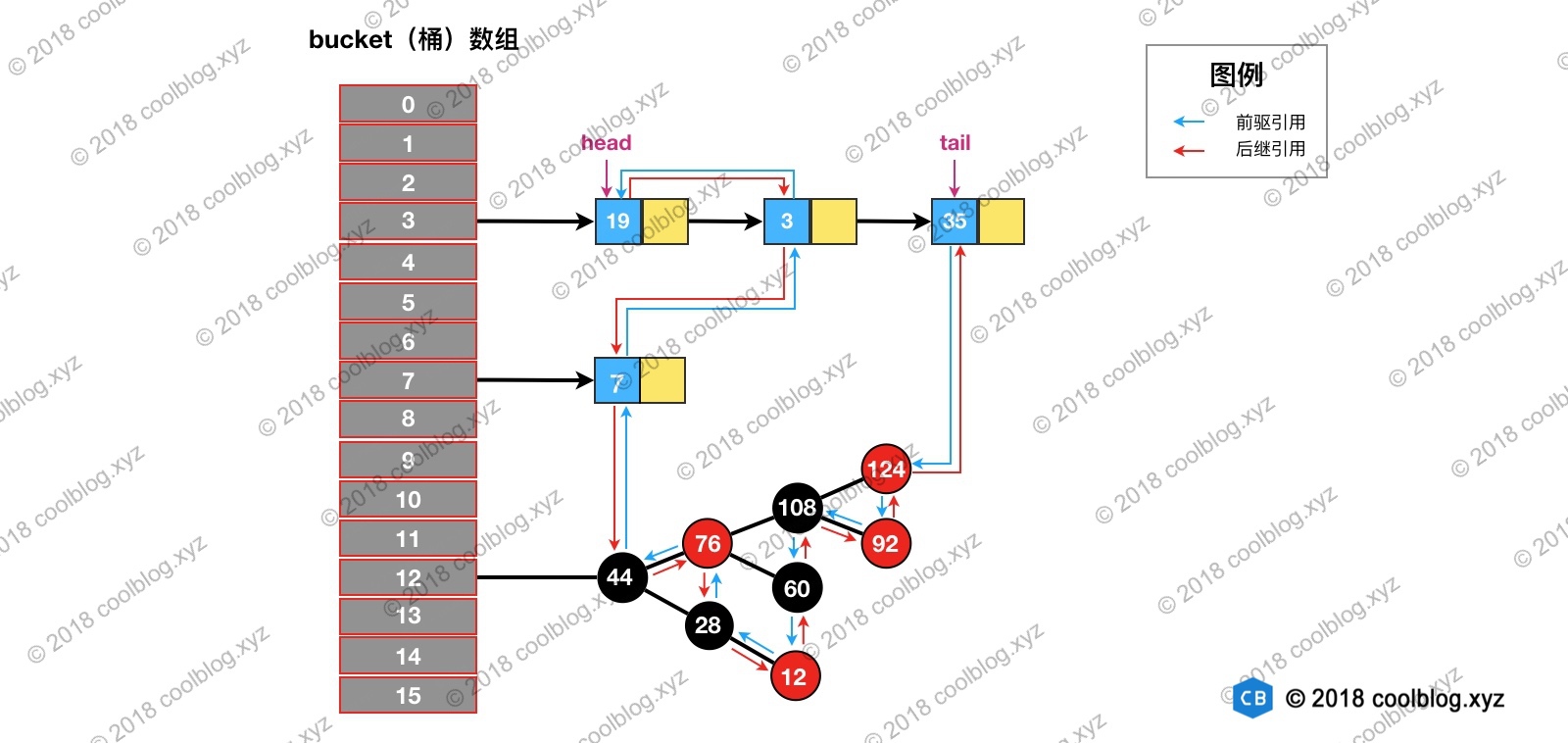
访问后,键值为3的节点将会被移动到双向链表的最后位置,其前驱和后继也会跟着更新。访问后的结构如下:
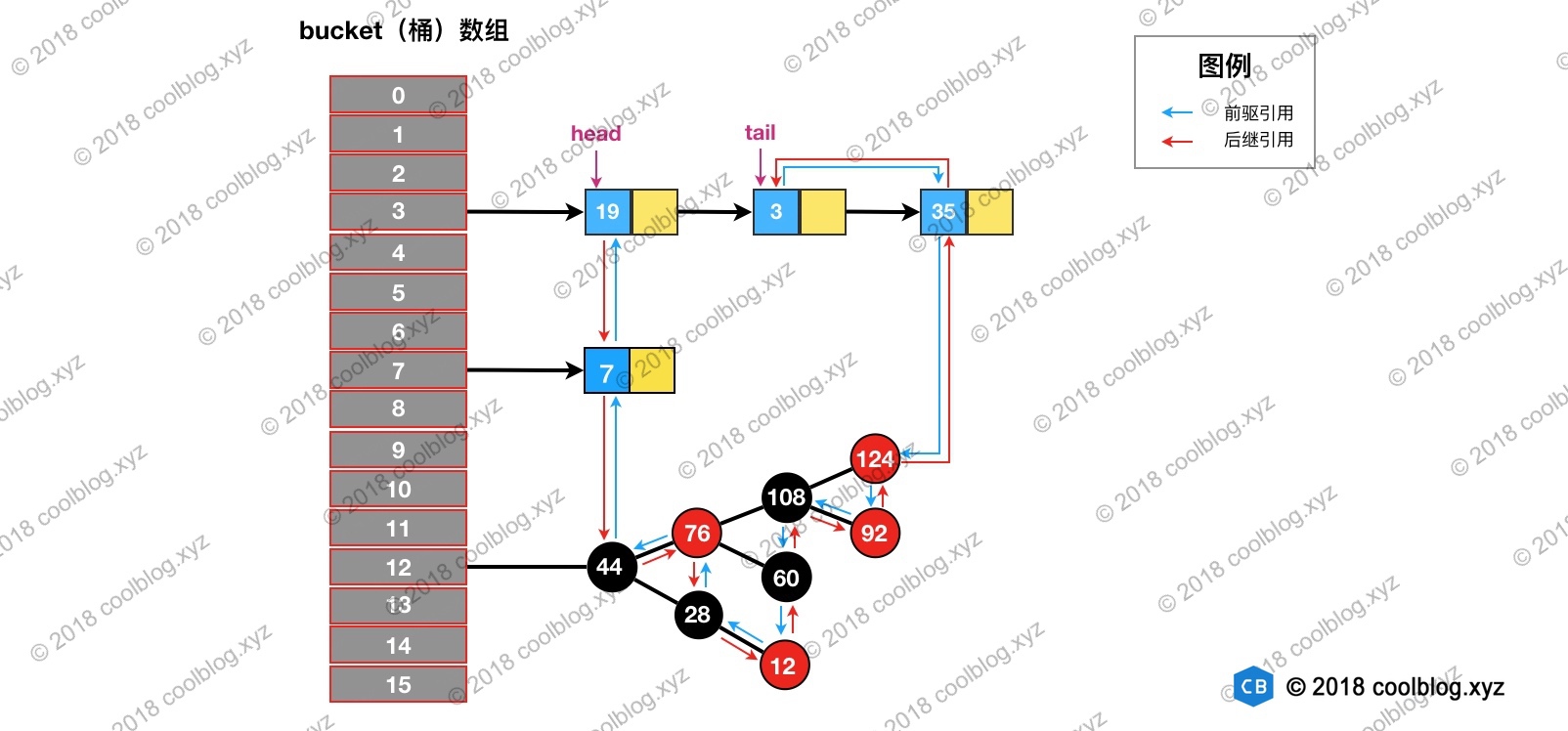
put()
LinkedHashMap并没有重写任何put方法。但是其重写了构建新节点的newNode()方法。
newNode()会在HashMap的putVal()方法里被调用,HashMap 的 put()方法会调用putVal() 方法。 实现的逻辑: 根据hash值找到散列位置i,先判断table[i]是否存在node ,如果不存在,则调用newNode()并赋值给table[i],如果存在,则插入到单链表或红黑树的后面。
1 | //在构建新节点时,构建的是LinkedHashMap.Entry不再是Node. |
2 | Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { |
3 | LinkedHashMap.Entry<K,V> p = |
4 | new LinkedHashMap.Entry<K,V>(hash, key, value, e); |
5 | linkNodeLast(p); |
6 | return p; |
7 | } |
重新后的newnode 只添加了一条逻辑, 把节点添加到双链表的尾部。
在HashMap 的putVal() 中有一个空方法就是为LinkedHashMap 预留的 :afterNodeAccess () 在HashMap 中它是一个空方法, 而在LinkedHashMap 中我们可以看到其实现:
1 | //回调函数,新节点插入之后回调 , 根据evict 和 判断是否需要删除最老插入的节点。如果实现LruCache会用到这个方法。 |
2 | void afterNodeInsertion(boolean evict) { // possibly remove eldest |
3 | LinkedHashMap.Entry<K,V> first; |
4 | //LinkedHashMap 默认返回false 则不删除节点 |
5 | if (evict && (first = head) != null && removeEldestEntry(first)) { |
6 | K key = first.key; |
7 | removeNode(hash(key), key, null, false, true); } |
8 | } |
9 | //LinkedHashMap 默认返回false 则不删除节点。 返回true 代表要删除最早的节点。通常构建一个LruCache会在达到Cache的上限是返回true |
10 | protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { |
11 | return false; |
12 | } |
如果我们要根据LinkedHashMap 实现一个LruCashed , 我们只需要继承LinkedHashMap ,重写removeEldestEntry, 当当前长度> 缓存长度, 返回true 即可。
注意,这里的插入有两重含义:
- 从
table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。 - 从
header的角度看,新的entry需要插入到双向链表的尾部。
remove()
与插入操作一样,LinkedHashMap 删除操作相关的代码也是直接用父类的实现。在删除节点时,父类的删除逻辑并不会修复 LinkedHashMap 所维护的双向链表。在删除及节点后,回调方法 afterNodeRemoval 会被调用。LinkedHashMap 覆写该方法,并在该方法中完成了移除被删除节点的操作。
1 | // HashMap 中实现 |
2 | public V remove(Object key) { |
3 | Node<K,V> e; |
4 | return (e = removeNode(hash(key), key, null, false, true)) == null ? |
5 | null : e.value; |
6 | } |
7 | |
8 | // HashMap 中实现 |
9 | final Node<K,V> removeNode(int hash, Object key, Object value, |
10 | boolean matchValue, boolean movable) { |
11 | Node<K,V>[] tab; Node<K,V> p; int n, index; |
12 | if ((tab = table) != null && (n = tab.length) > 0 && |
13 | (p = tab[index = (n - 1) & hash]) != null) { |
14 | Node<K,V> node = null, e; K k; V v; |
15 | if (p.hash == hash && |
16 | ((k = p.key) == key || (key != null && key.equals(k)))) |
17 | node = p; |
18 | else if ((e = p.next) != null) { |
19 | if (p instanceof TreeNode) {...} |
20 | else { |
21 | // 遍历单链表,寻找要删除的节点,并赋值给 node 变量 |
22 | do { |
23 | if (e.hash == hash && |
24 | ((k = e.key) == key || |
25 | (key != null && key.equals(k)))) { |
26 | node = e; |
27 | break; |
28 | } |
29 | p = e; |
30 | } while ((e = e.next) != null); |
31 | } |
32 | } |
33 | if (node != null && (!matchValue || (v = node.value) == value || |
34 | (value != null && value.equals(v)))) { |
35 | if (node instanceof TreeNode) {...} |
36 | // 将要删除的节点从单链表中移除 |
37 | else if (node == p) |
38 | tab[index] = node.next; |
39 | else |
40 | p.next = node.next; |
41 | ++modCount; |
42 | --size; |
43 | afterNodeRemoval(node); // 调用删除回调方法进行后续操作 |
44 | return node; |
45 | } |
46 | } |
47 | return null; |
48 | } |
49 | |
50 | // LinkedHashMap 中覆写 |
51 | void afterNodeRemoval(Node<K,V> e) { // unlink |
52 | LinkedHashMap.Entry<K,V> p = |
53 | (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; |
54 | // 将 p 节点的前驱后后继引用置空 |
55 | p.before = p.after = null; |
56 | // b 为 null,表明 p 是头节点 |
57 | if (b == null) |
58 | head = a; |
59 | else |
60 | b.after = a; |
61 | // a 为 null,表明 p 是尾节点 |
62 | if (a == null) |
63 | tail = b; |
64 | else |
65 | a.before = b; |
66 | } |
删除的过程并不复杂,上面这么多代码其实就做了三件事:
- 根据 hash 定位到桶位置
- 遍历链表或调用红黑树相关的删除方法
- 从 LinkedHashMap 维护的双链表中移除要删除的节点
举个例子说明一下,假如我们要删除下图键值为 3 的节点。
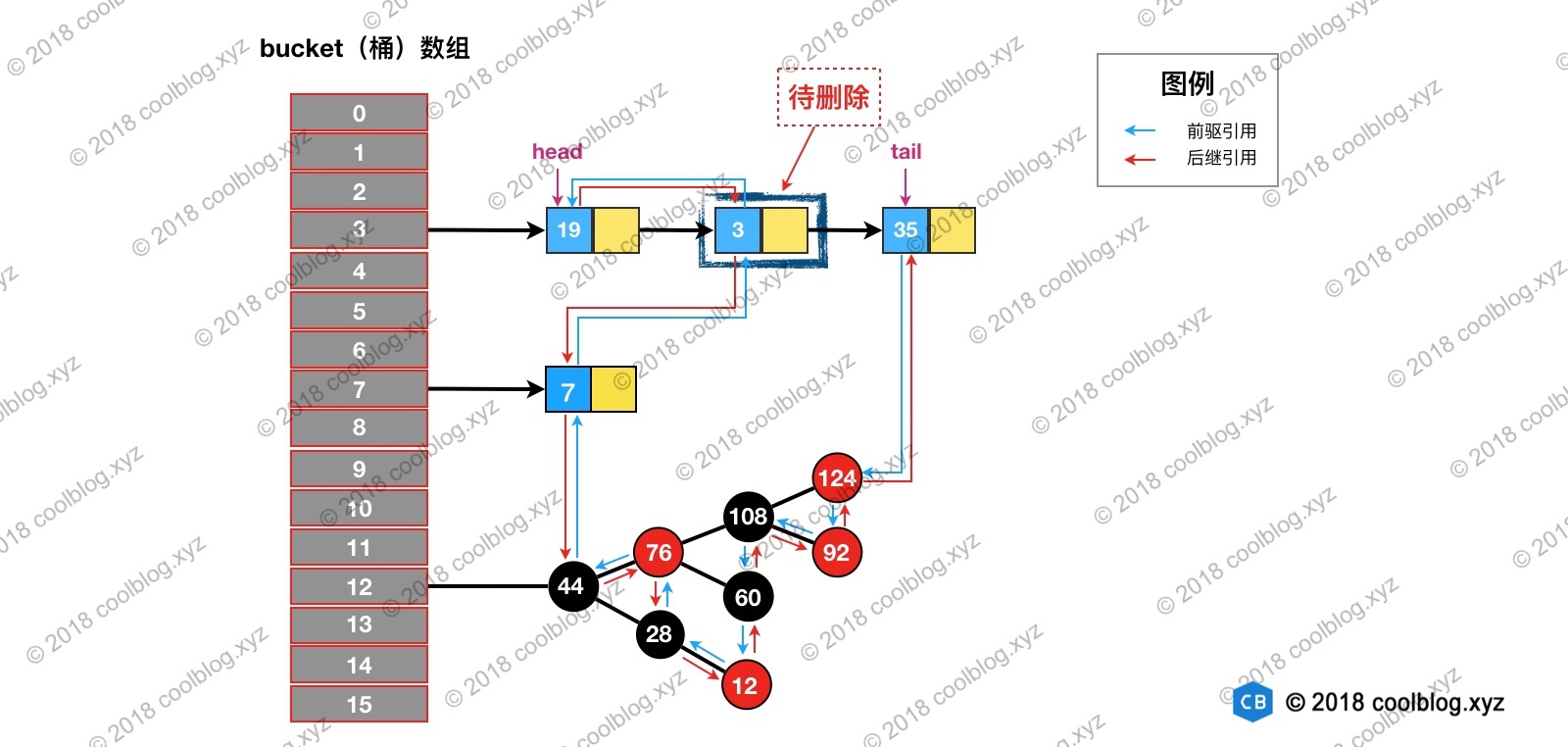
根据 hash 定位到该节点属于3号桶,然后在对3号桶保存的单链表进行遍历。找到要删除的节点后,先从单链表中移除该节点。如下:
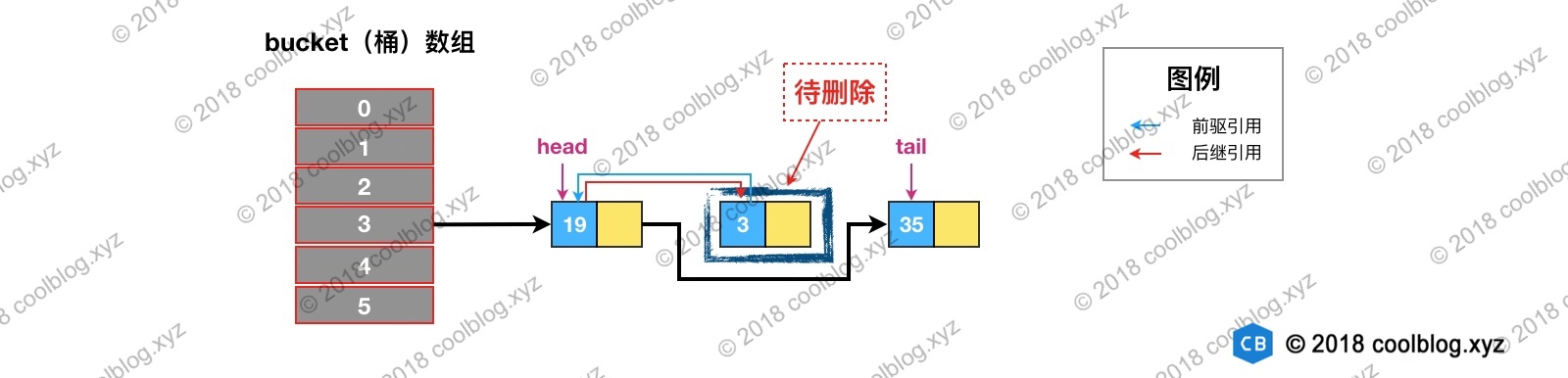
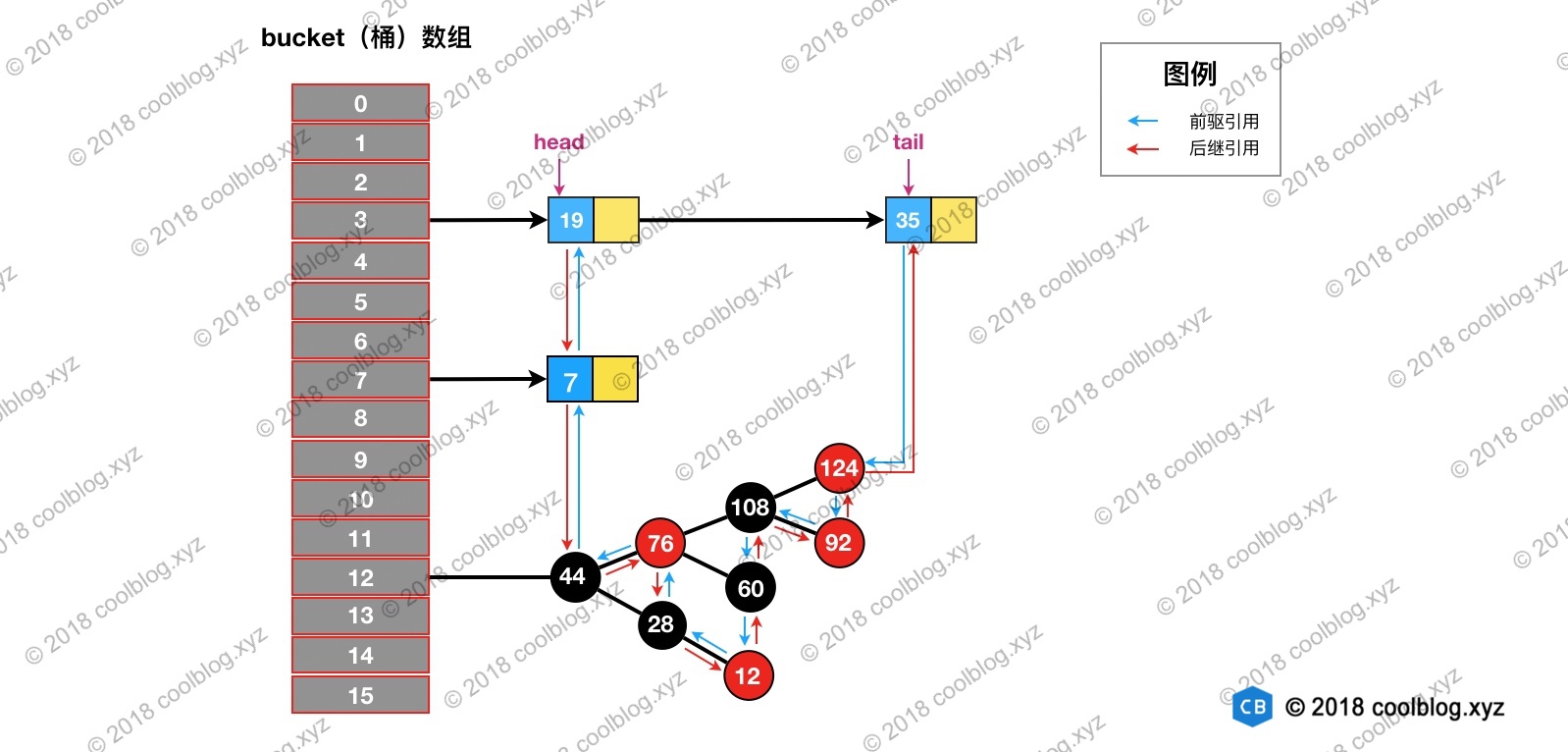
然后再双向链表中移除该节点:
基于 LinkedHashMap 实现缓存
通过继承 LinkedHashMap 实现了一个简单的 LRU 策略的缓存。
当我们基于 LinkedHashMap 实现缓存时,通过覆写removeEldestEntry方法可以实现自定义策略的 LRU 缓存。比如我们可以根据节点数量判断是否移除最近最少被访问的节点,或者根据节点的存活时间判断是否移除该节点等。本节所实现的缓存是基于判断节点数量是否超限的策略。在构造缓存对象时,传入最大节点数。当插入的节点数超过最大节点数时,移除最近最少被访问的节点。实现代码如下:
1 | public class SimpleCache<K, V> extends LinkedHashMap<K, V> { |
2 | |
3 | private static final int MAX_NODE_NUM = 100; |
4 | |
5 | private int limit; |
6 | |
7 | public SimpleCache() { |
8 | this(MAX_NODE_NUM); |
9 | } |
10 | |
11 | public SimpleCache(int limit) { |
12 | super(limit, 0.75f, true); |
13 | this.limit = limit; |
14 | } |
15 | |
16 | public V save(K key, V val) { |
17 | return put(key, val); |
18 | } |
19 | |
20 | public V getOne(K key) { |
21 | return get(key); |
22 | } |
23 | |
24 | public boolean exists(K key) { |
25 | return containsKey(key); |
26 | } |
27 | |
28 | /** |
29 | * 判断节点数是否超限 |
30 | * @param eldest |
31 | * @return 超限返回 true,否则返回 false |
32 | */ |
33 | |
34 | protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { |
35 | return size() > limit; |
36 | } |
37 | } |
测试代码
1 | public class SimpleCacheTest { |
2 | |
3 | |
4 | public void test() throws Exception { |
5 | SimpleCache<Integer, Integer> cache = new SimpleCache<>(3); |
6 | |
7 | for (int i = 0; i < 10; i++) { |
8 | cache.save(i, i * i); |
9 | } |
10 | |
11 | System.out.println("插入10个键值对后,缓存内容:"); |
12 | System.out.println(cache + "\n"); |
13 | |
14 | System.out.println("访问键值为7的节点后,缓存内容:"); |
15 | cache.getOne(7); |
16 | System.out.println(cache + "\n"); |
17 | |
18 | System.out.println("插入键值为1的键值对后,缓存内容:"); |
19 | cache.save(1, 1); |
20 | System.out.println(cache); |
21 | } |
22 | } |
在测试代码中,设定缓存大小为3。在向缓存中插入10个键值对后,只有最后3个被保存下来了,其他的都被移除了。然后通过访问键值为7的节点,使得该节点被移到双向链表的最后位置。当我们再次插入一个键值对时,键值为7的节点就不会被移除。